Welcome to the engine room of Artificial Intelligence optimization! If you have ever interacted with Large Language Models (LLMs) like GPT-5, Claude, or Gemini, you have experienced the power of “Generalist” AI. But to transform a Swiss Army knife into a precision scalpel, there is a crucial step: Fine-tuning.
This article explores the depths of this technique, which allows a model to move from “knowing a little about everything” to “perfectly mastering your specific domain.”
What is Fine-Tuning?
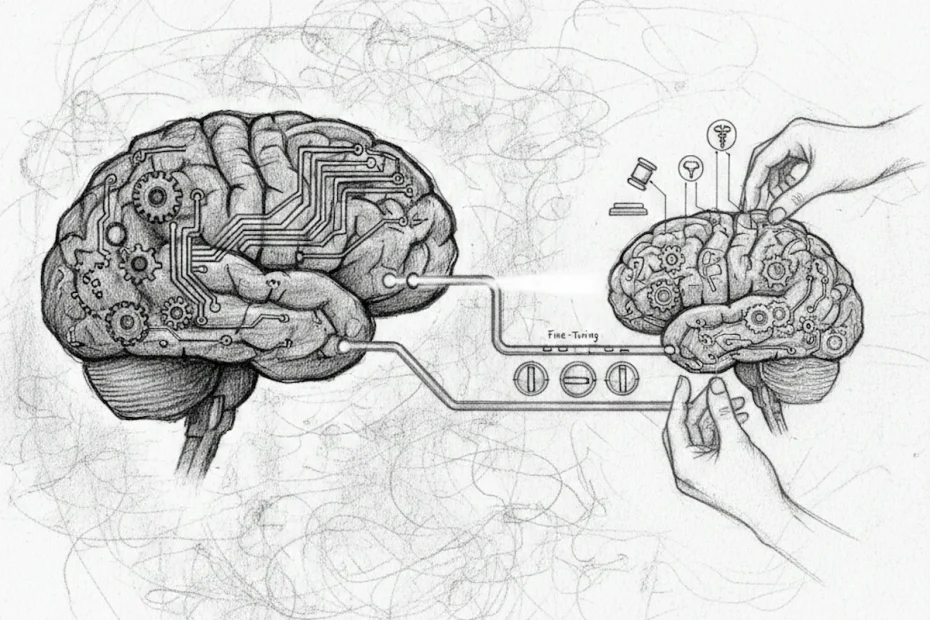
Fine-tuning is a supervised learning process that involves taking a pre-trained model (the “base model”), already trained on massive amounts of data, and training it further on a much smaller, specific, and high-quality dataset.
Imagine hiring a brilliant student who has just graduated with a general degree. They possess immense general knowledge and excellent writing skills. However, they know nothing about your firm’s specific legal procedures or the technical jargon of your aerospace factory. Fine-tuning is the internal training period where you provide them with specific manuals so they can become an in-house expert.
Pre-training vs. Fine-tuning
To understand one, you must grasp the other. Pre-training is a gargantuan phase where the AI “ingests” the web, books, and code to learn the structure of language and world concepts. This is where the initial synaptic weights are defined.
Fine-tuning comes after. We don’t start from scratch (which would cost millions of dollars); we simply adjust the existing sliders so that the model’s responses align with a specific style, format, or knowledge base.
Why choose Fine-Tuning?
While not always necessary, fine-tuning becomes a strategic requirement in several key scenarios:
1. Mastering tone and style
If you want your AI to speak like a specific brand persona, write emails that strictly follow your company’s editorial charter, or adopt a precise empathetic tone for customer support, fine-tuning is the most robust solution.
2. Acquiring complex jargon
In medical, legal, or ultra-technical sectors, terms carry nuances that general models might miss. Fine-tuning anchors these specific definitions into the “brain” of the AI.
3. Response structuring
Sometimes, you don’t need a long essay; you need a very strict format (such as specific JSON, code blocks, or one-sentence answers). By showing the model thousands of examples during fine-tuning, the AI adopts this format naturally without needing constant reminders in the prompt.
4. Cost and latency reduction
A fine-tuned model can often achieve better results with shorter instructions (prompts). Less text in the prompt means fewer tokens consumed, resulting in lower costs and faster response times.
Technical mechanics: Under the hood
Technically, fine-tuning modifies the weights of the neural network parameters. During this phase, backpropagation is used. We present a question to the model, it generates an answer, we compare that answer to the “ground truth” (the training dataset), and we slightly adjust the internal connections to reduce the error.
Modern variants: PEFT and LoRA
Training billions of parameters is resource-intensive. This is why techniques like PEFT (Parameter-Efficient Fine-Tuning) were developed. The most famous is LoRA (Low-Rank Adaptation). Instead of modifying all the model’s parameters, we add small, additional computational layers that are trained independently. It is fast, lightweight, and incredibly effective.
Related: A comprehensive guide to Machine Learning
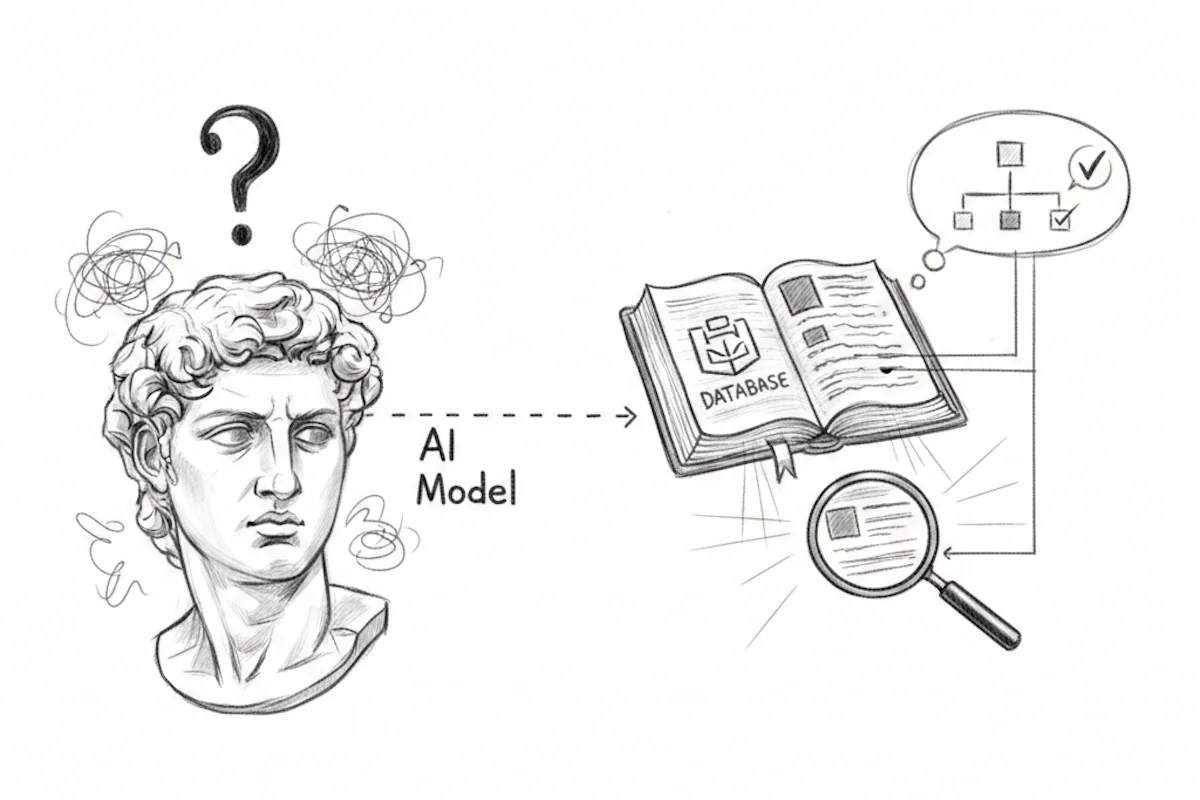
Fine-Tuning vs. RAG: The great debate
It is impossible to discuss fine-tuning without mentioning RAG (Retrieval-Augmented Generation).
- RAG gives the AI a book to look up answers in real-time (short-term/external memory).
- Fine-tuning makes the AI memorize the book (long-term/internal memory).
Fine-tuning is excellent for form (how to say things), while RAG is often better for facts (providing the latest up-to-date information), as updating a database is simpler than re-training a model every day.
Steps for successful fine-tuning
- Data preparation: This is the most time-consuming step. You must curate high-quality “Instruction/Response” pairs. Quality beats quantity: 500 perfect examples are worth more than 10,000 mediocre ones.
- Base model selection: Choose an architecture (Llama 3, Mistral, etc.) suited to the language and task.
- Training: Running the computations on Graphics Processing Units (GPUs).
- Evaluation: Testing the model on data it has never seen to ensure it hasn’t fallen into “overfitting,” where it simply mimics examples without understanding.
Limitations to consider
Fine-tuning is not a magic wand. It carries certain risks:
- Catastrophic forgetting: By learning a new task too intensely, the model might forget how to perform simple tasks it was originally good at.
- Hardware costs: Even with techniques like LoRA, significant computing power is required.
- Obsolescence: Once a model is trained, its knowledge is frozen as of the training end date.
Beyond the generalist model
Fine-tuning is the ultimate stage of personalization in Artificial Intelligence. It is what transforms a generic technology into a proprietary strategic asset for a business.
By mastering the art of adjusting models, you no longer just use AI, you shape it in your own image.
Want to master the world of AI? Check out the full AI Glossary written by our expert team over at Free AI Online.